ESG has historically referred to “data protection” as a spectrum of activities that include backup, snapshots, and replication, as shown here:
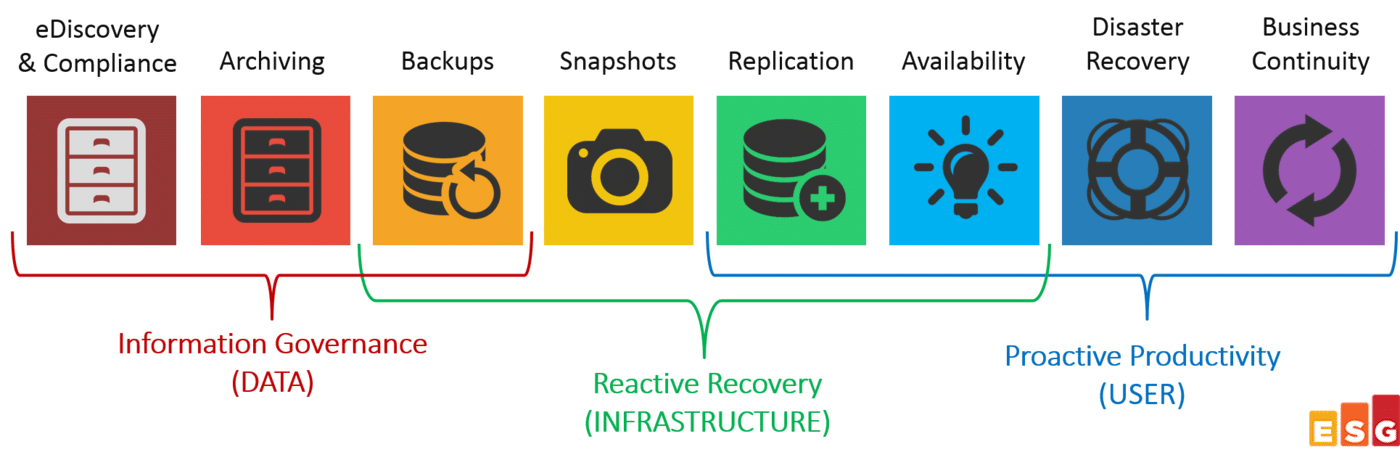
However, those actions are simply making copies, derived and stored in different ways, but still just copies of volumes, disks, folders, and other data repositories. The problem is that within even one of those repositories, not all data is equal.
- Not all data should be retained for the same length of time.
- Not all data should be deleted on similar schedules.
- Not all data should be protected with the same frequency.
- Not all data should have as much agility and availability/recoverability.
But if all you can do is make copies of volumes, disks, folders, etc. then you inevitably have a ceiling to your solution’s usefulness—which will in turn limit your organization’s IT agility and its responsiveness to leadership and business units.
The secret sauce to lift data protection up to data management is having contextual insight on the information held within the data sets. For most organizations, that requires some level of archival mechanisms. Not necessarily a full-blown and separate archive product/service, but you need at least some capabilities to not only inventory the files within your backups, but also actually understand which data has regulatory impact, which data has business criticality, etc. You need to know what you have.
If you know what you have …
- Then you can determine which data should be retained and for how long.
- Then you can delete the data that is no longer needed due to either stagnancy or regulations.
- Then you can automatically apply protection/preservation/availability policies.
If you don’t know what you have, then all you can do is make copies.