Most organizations supplement traditional backup with some combination of snapshots, replication and archiving to achieve more comprehensive data protection. They are using what we at ESG refer to as the Spectrum of Data Protection.
Innovative data protection vendors, meanwhile, are constantly reacting to the changing IT landscape in their attempts to give their customers and prospects what they are looking for. With backup no longer enough for many organizations, data protection startups and industry dominators are stretching out and evolving in one of two tracks: data availability or data management.
Let’s take a look at these complementary yet decisively distinct branches of the data protection family tree.
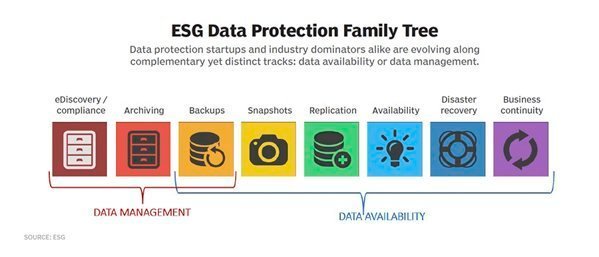
Data availability
The primary focus of data availability is to ensure user productivity though an infrastructure that is reactive in its recoverability across a diverse range of scenarios, delivering a wider set of recovery point objective and recovery time objective capabilities than what backup alone can do (essentially, the right three-quarters of the family tree diagram).
A significant challenge in embracing a comprehensive data protection strategy, instead of simply a backup strategy, is the myriad methods employed. They can cause drastic over-protection or under-protection. While most data still requires backups (routine, multiversion retention over an extended period of time), the agile recovery needed for heightened availability often comes from snapshots and replicas before even attempting a restore. And those activities are complemented by application- or platform-specific availability/clustering/failover mechanisms.
The key to a successful data availability strategy then becomes a heterogeneous control plane across the multiple data protection methods, and a common catalog to mitigate over-/under-protection while unlocking all of the copies available for recovery.
Data management
Data management can be seen as both the reactive and proactive result of a truly mature IT infrastructure that has evolved beyond data protection. From a reactive perspective, all copies of data created through both data protection and data availability initiatives are economically unsustainable without data management.
That’s because primary production storage and secondary/tertiary protection storage are each growing faster than IT budgets. As such, organizations need to look at how they can unlock additional business value from their sprawling data protection infrastructure by leveraging otherwise dormant copies of information for reporting, test/dev enablement and analytics. Most in the industry call this copy data management, which was pioneered by startups and is now starting to be championed by industry leaders as an evolution of their broader data protection portfolios.
The proactive side of data management encompasses data protection areas such as e-discovery and compliance, archiving and, of course, backups (essentially, the left one-third of the family tree diagram). Here, organizations embrace real archival technologies instead of just long-term backups. They combine those technologies with processes and corporate culture changes to enable information governance and regulatory compliance.
For any of this to happen (data management, data availability or even just comprehensive data protection), organizations need a framework that we at ESG refer to as “The 5 Cs of Data Protection”:
Containers: Organizations should have multiple containers (repositories) for production storage and protection storage, including tape, disk and cloud.
Conduits: Enterprises will likely have multiple conduits (data movers). They frequently include not only snapshot and replication mechanisms that are often hardware based, but also multiple backup applications for general-purpose platforms and perhaps tools specifically for databases, VMs or SaaS.
Control: Because of the presumed heterogeneity of containers and conduits, organizations should seek out a single control plane (policy engine) that can ensure adequate protection across the underlying widgets without over- or under-protection.
Catalog: This needs to be a real catalog of what you have stored across those containers, regardless of which conduits created them. While some vendors might claim a rich catalog, they merely have an index of backup jobs, perhaps with enumerated file sets, instead of something that recognizes the contextual or embedded business value of the information within the data that has been stored.
Consoles: Lastly, to make sense of the whole data protection environment, most organizations need multiple consoles, whereby different roles can provide contextual insight — though vCenter plug-ins, System Center packs, workload (e.g., Oracle/SQL) connectors — as well as a ubiquitous lens across the vastly heterogeneous arrays and backup/replication technologies for a view that enables IT operations specialists to gain insights from their catalog and drive their control plane.
You can read more about The 5 Cs of Data Protection on ESG’s blog.
[Originally posted on TechTarget as a recurring columnist]